-
June 2018: GPT, the first pretrained Transformer model, used for fine-tuning on various NLP tasks and obtained state-of-the-art results
-
October 2018: BERT, another large pretrained model, this one designed to produce better summaries of sentences (more on this in the next chapter!)
-
February 2019: GPT-2, an improved (and bigger) version of GPT that was not immediately publicly released due to ethical concerns
-
October 2019: DistilBERT, a distilled version of BERT that is 60% faster, 40% lighter in memory, and still retains 97% of BERT’s performance
-
October 2019: BART and T5, two large pretrained models using the same architecture as the original Transformer model (the first to do so)
-
May 2020, GPT-3, an even bigger version of GPT-2 that is able to perform well on a variety of tasks without the need for fine-tuning (called zero-shot learning)
So basically, BERT - DistilBERT - GPT-2 - BART - GPT-3

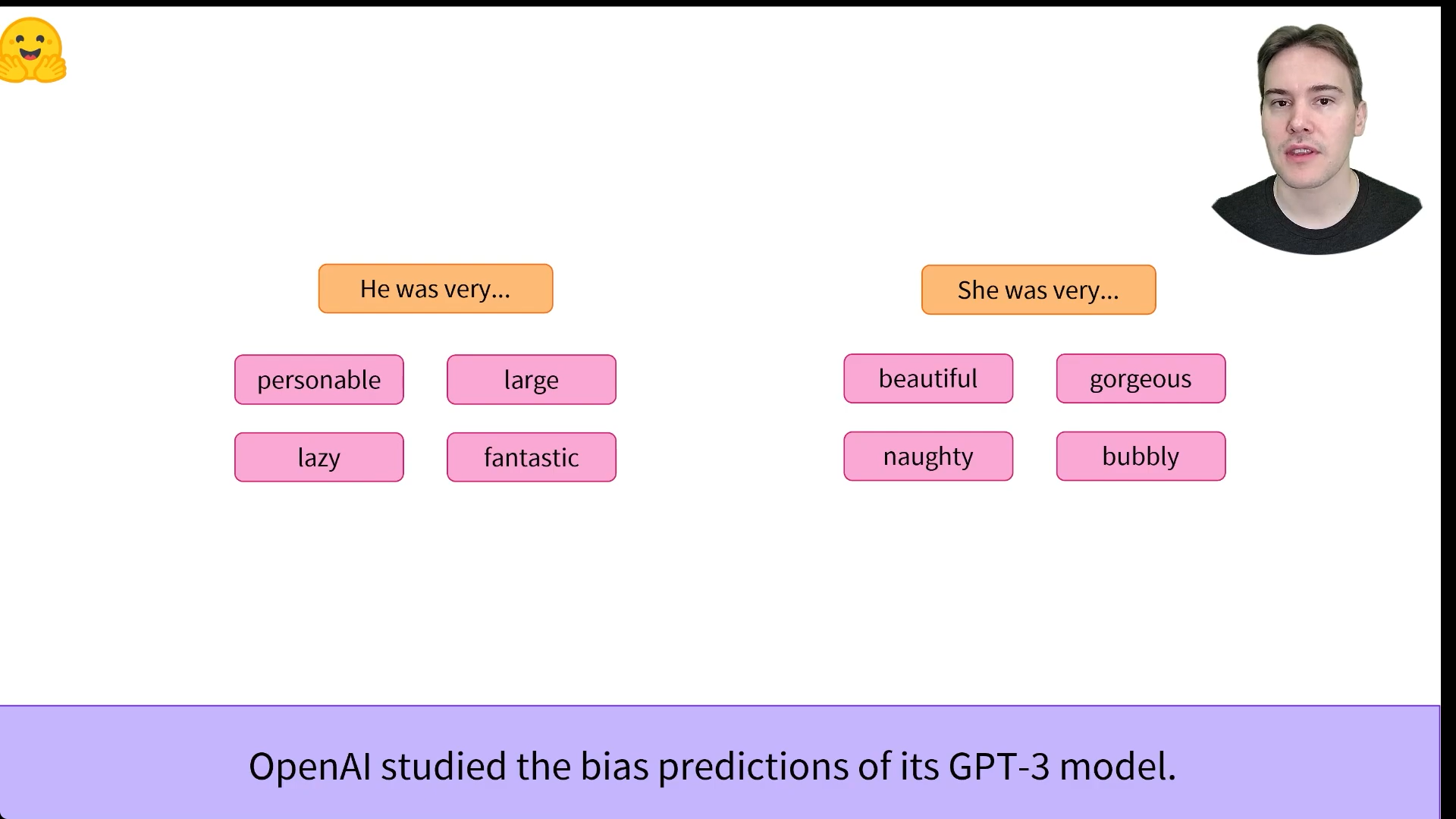
For example, one could leverage a pretrained model trained on the English language and then fine-tune it on an arXiv corpus, resulting in a science/research-based model. The fine-tuning will only require a limited amount of data: the knowledge the pretrained model has acquired is “transferred,” hence the term transfer learning.

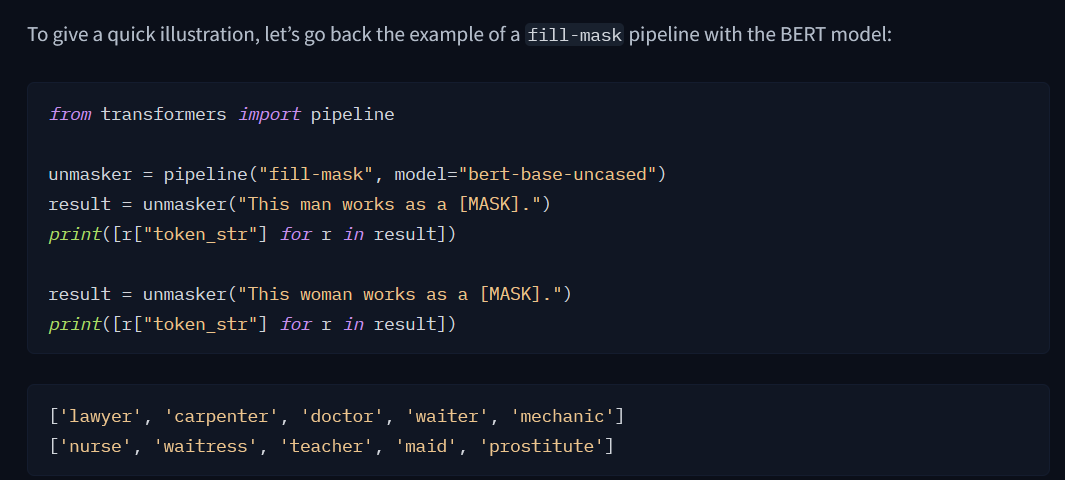
Mel spectrum is more close to how humans hear
- in a logarithmic scale