-
- Selçuk hocadan yardım istediğim muhabbet buydu, farklı temellerde bile olsalar aslında göründüğünden daha fazla ortak nokta ve bağıntı var.
- Bunu syntax la daha iyi çözebilirim
-
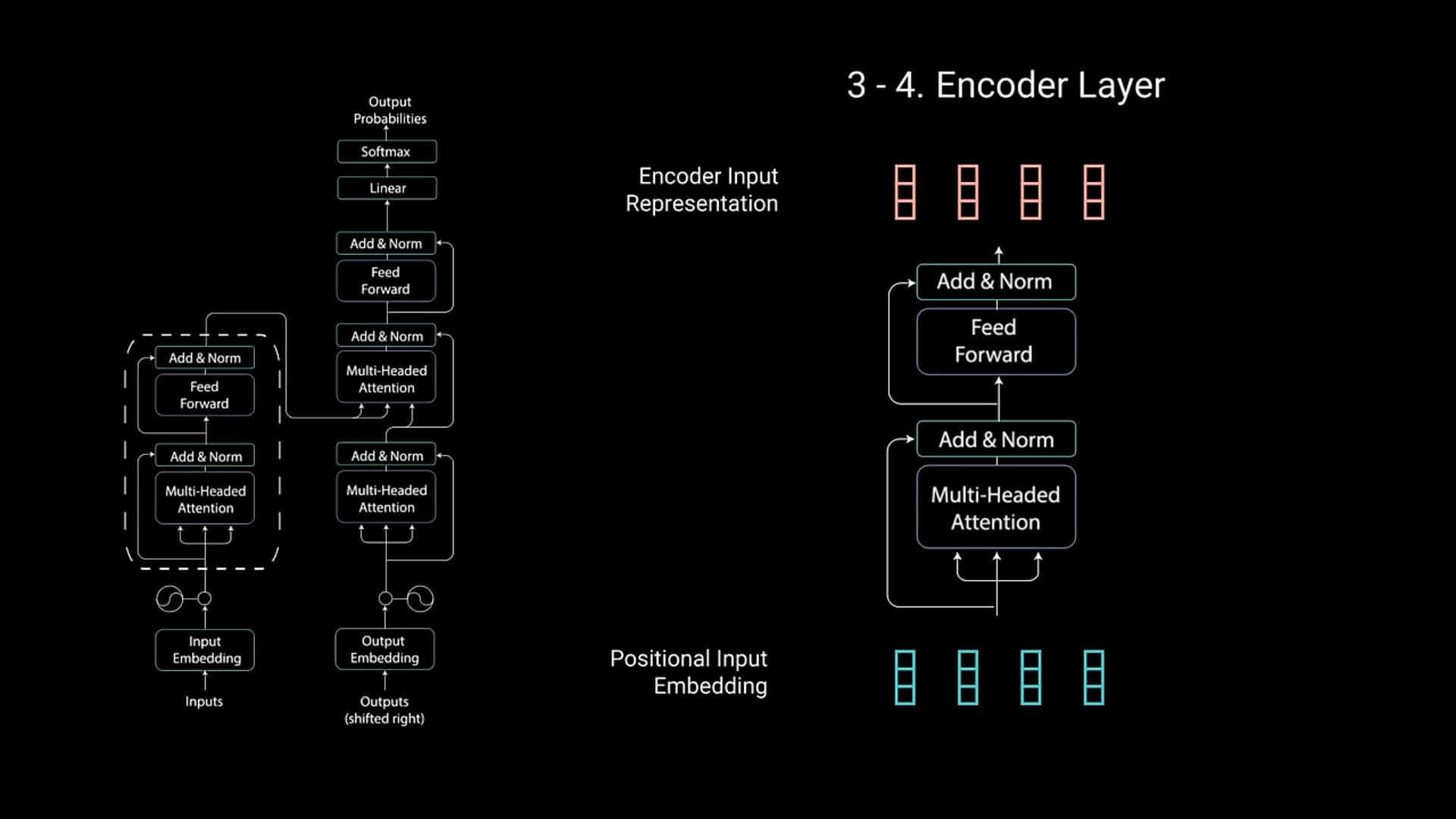
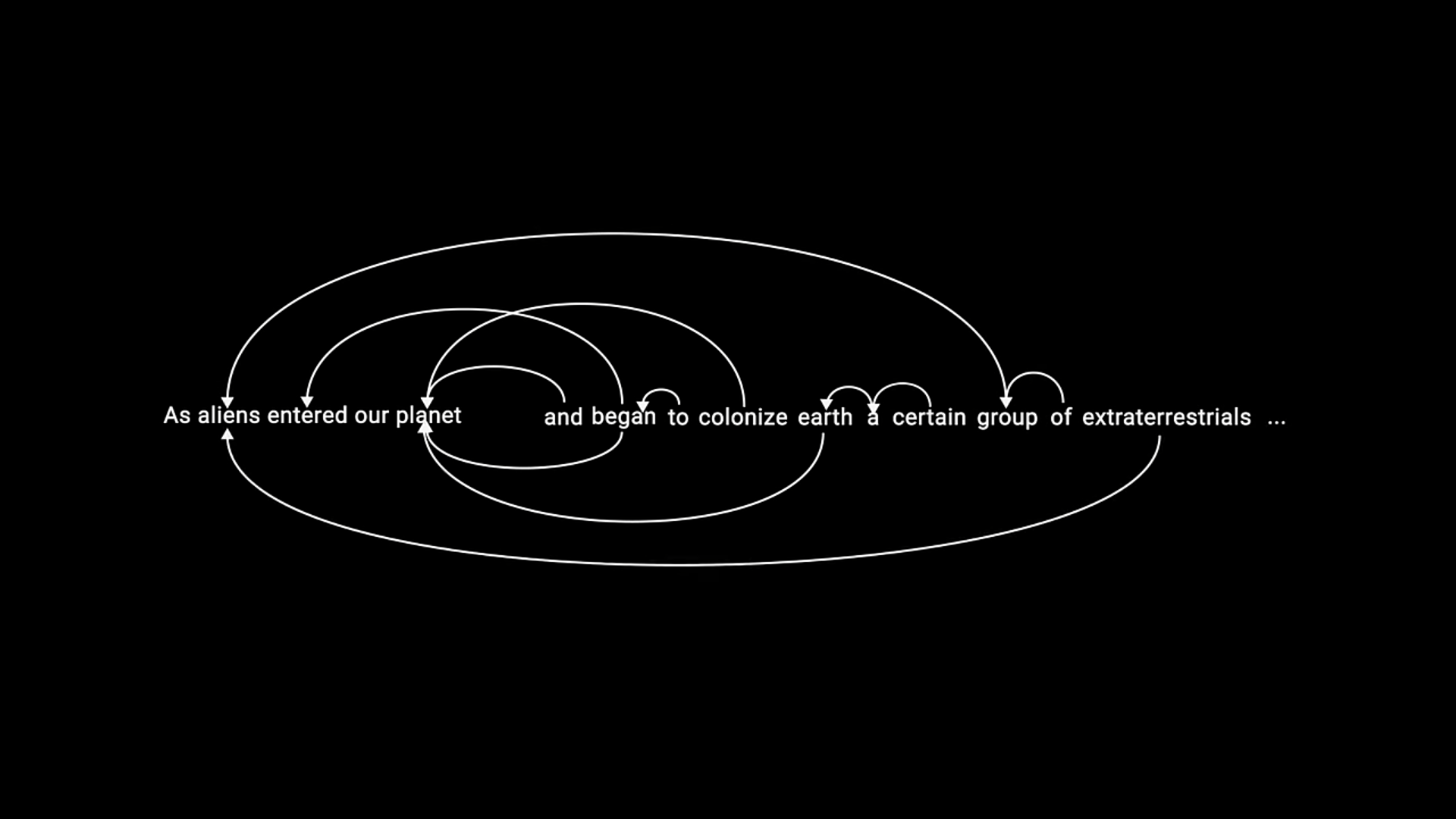
Most important bit of transformers, the difference of Attention Mechanism from the old ways

- Rnn’s have a shorter memory
-
Input Embedding is processed by assigning it a continuous value that represents how much weight(or attention?) should be given to a word.
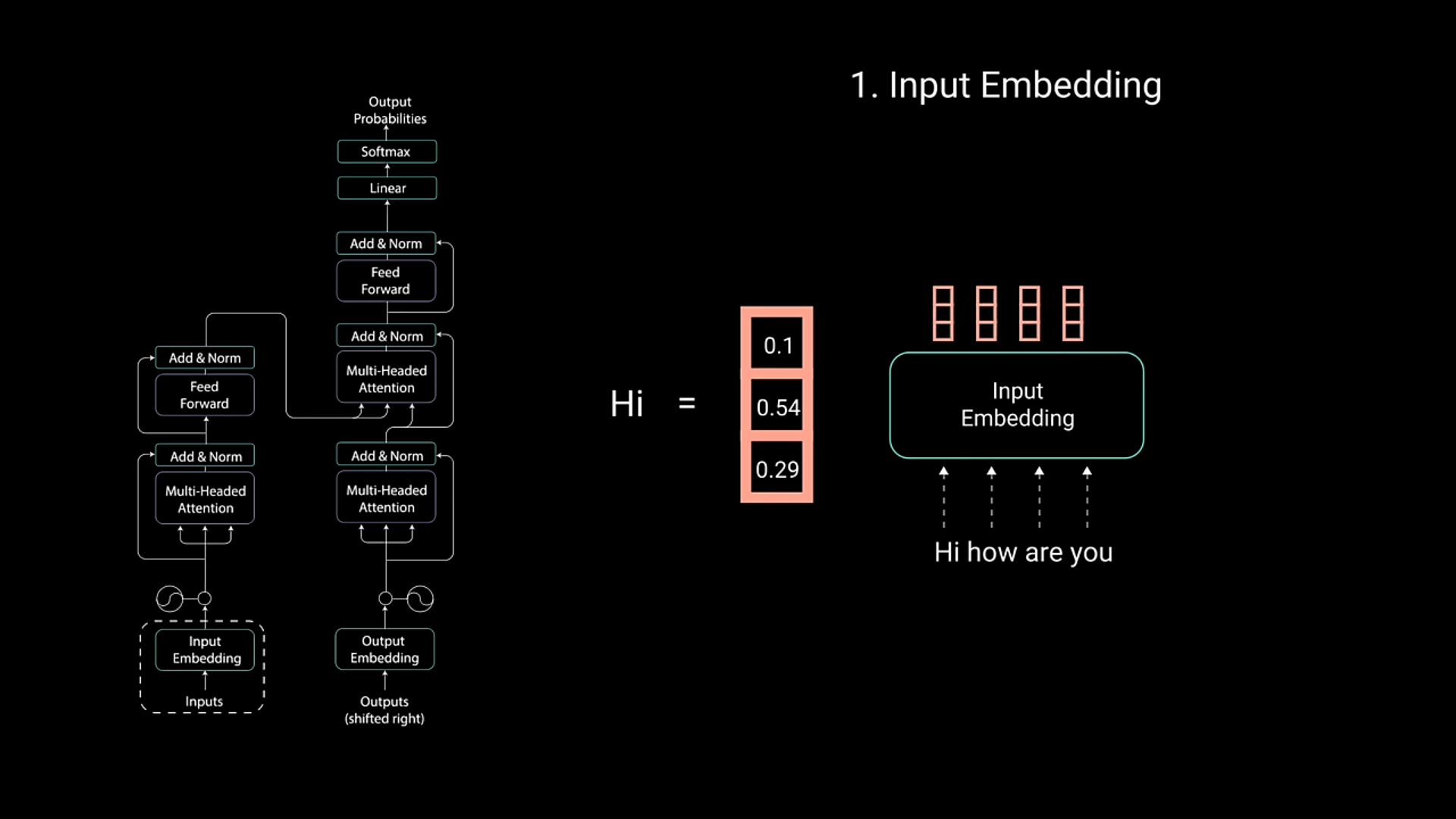
- In this example, hi is given the most importance in order to construct what the input is like.
- “Hi, how are you?” mostly necessitates a question afterwards or it is followed by a question sentence “how are you?“. So we give hi the most significance and lower the values of things like “was”
-
Encoder Layer consists of Multi-Headed Attention and Feed forward, with “Add & Norm” containing “Residual Info”
-
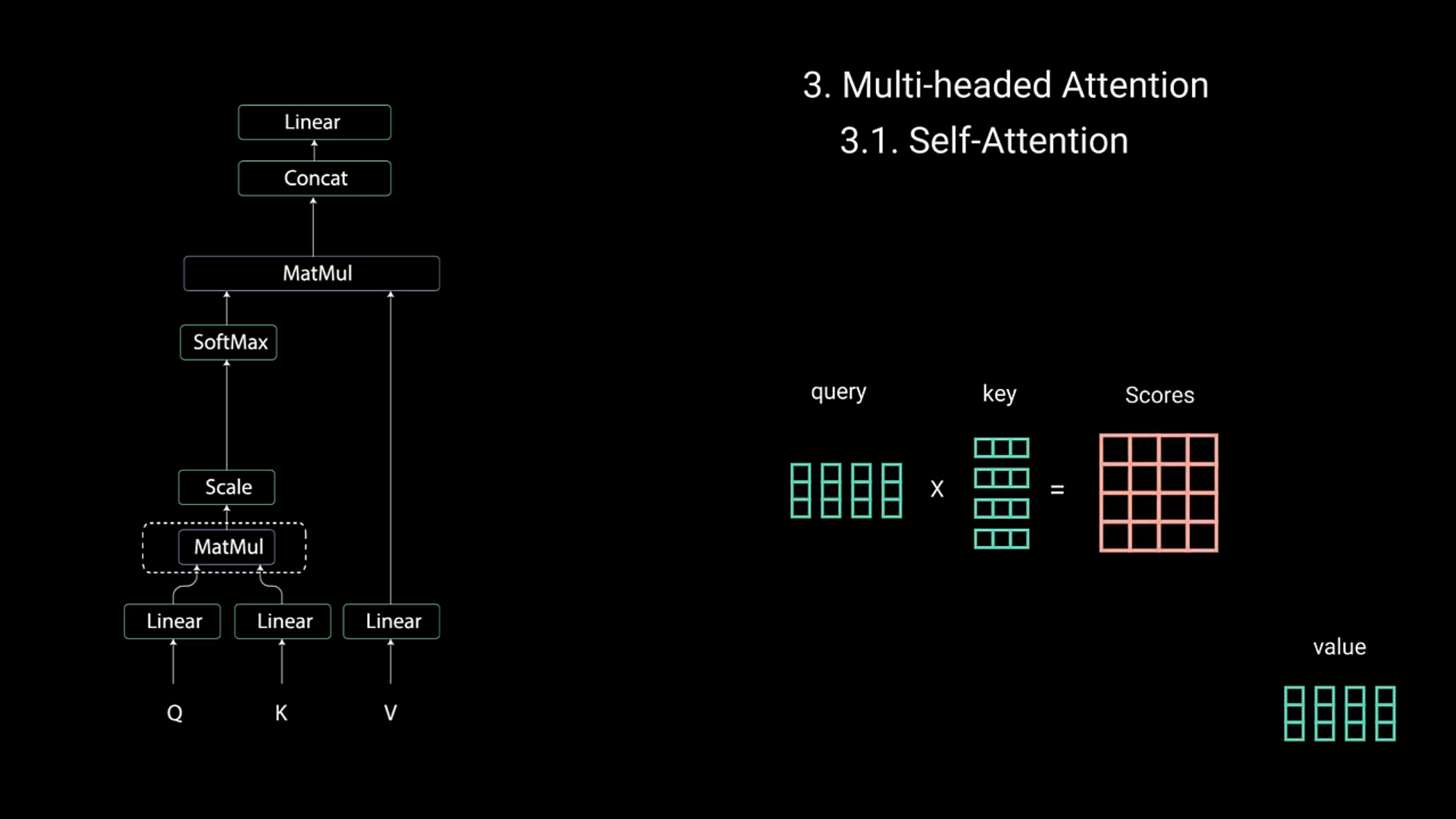
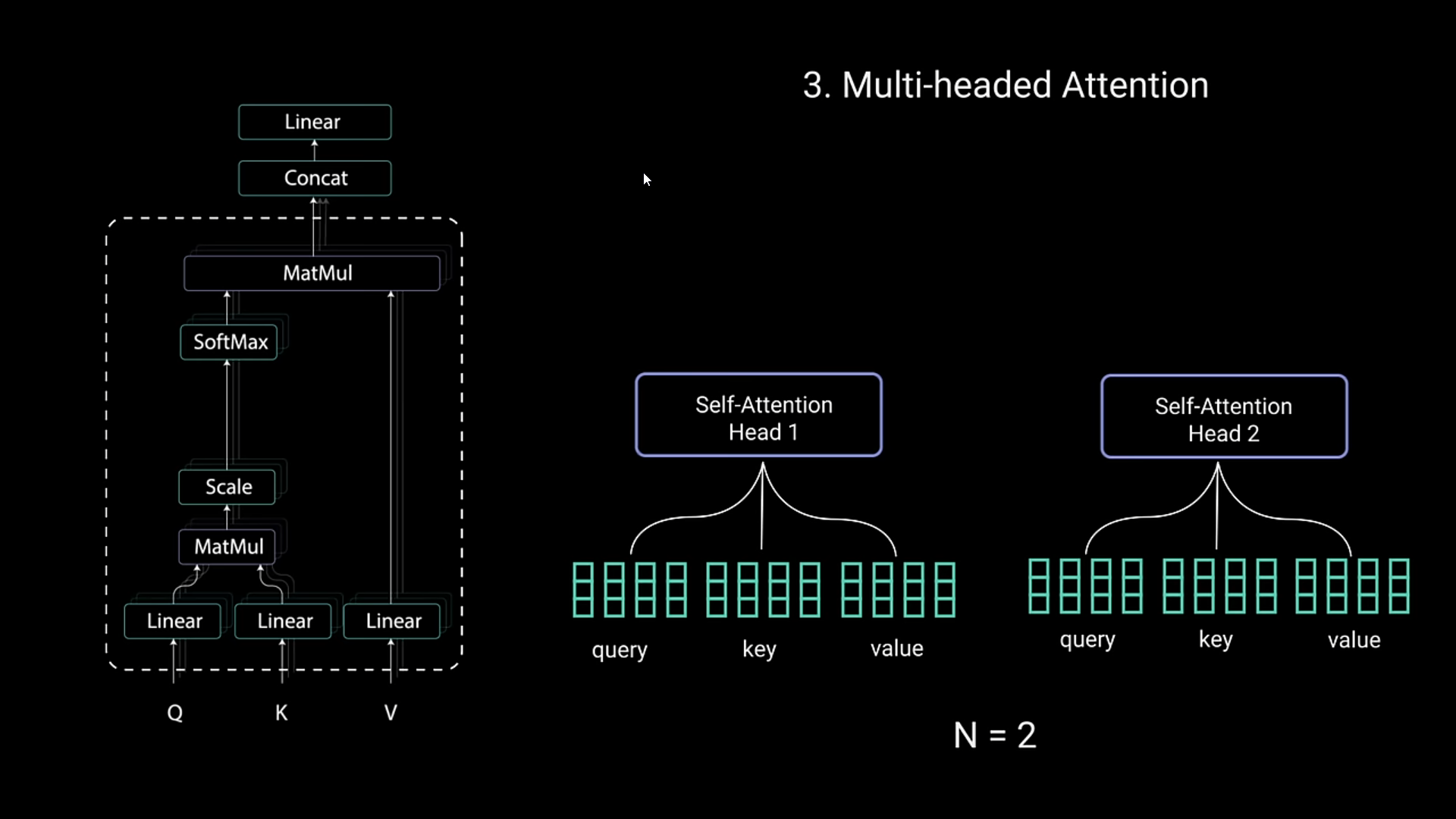
Multi-Headed Attention
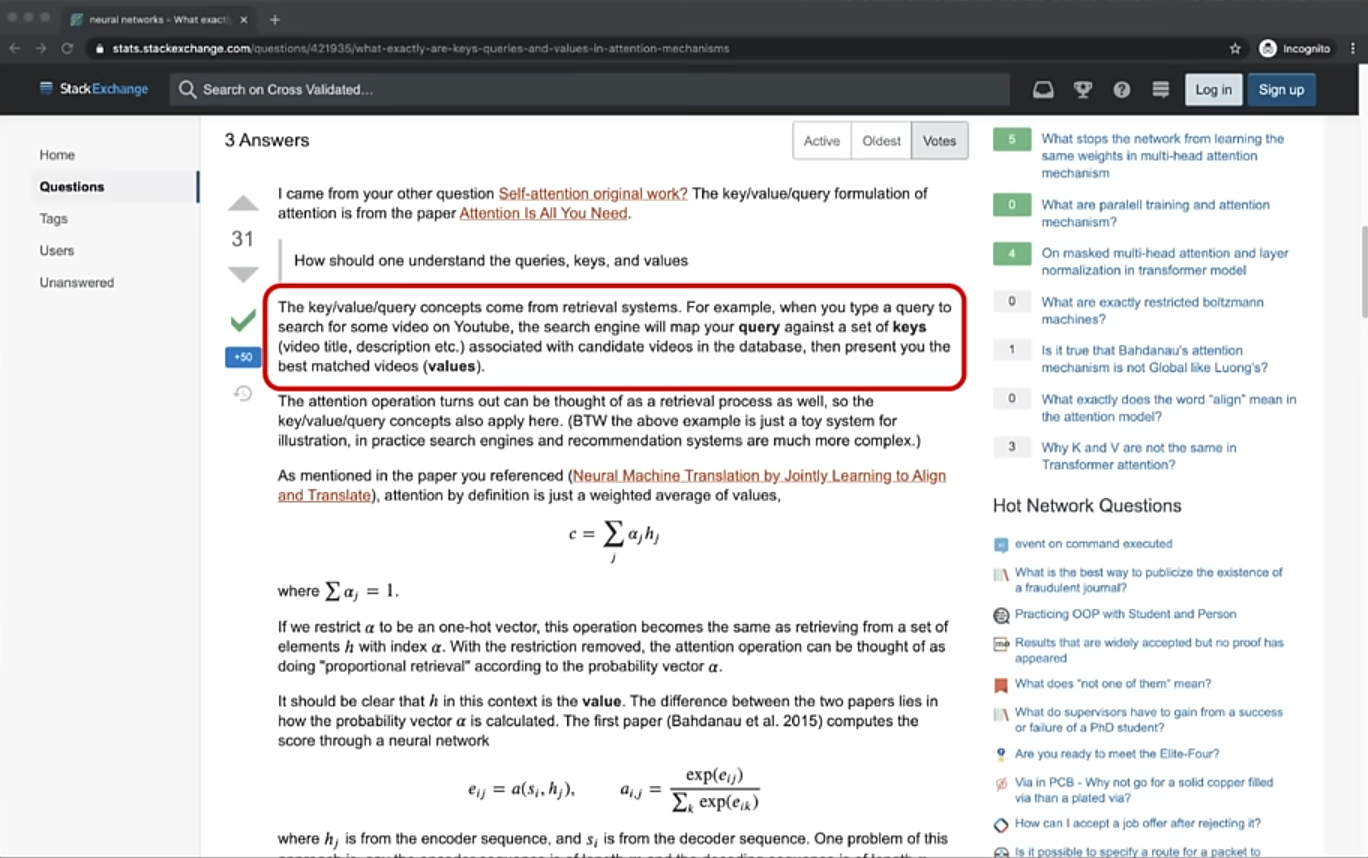
- Self attention’s base is created by Query, Key and Value prompts. You query youtube with keys like transformers, losing focus… and it gives you an output of values that you searched for
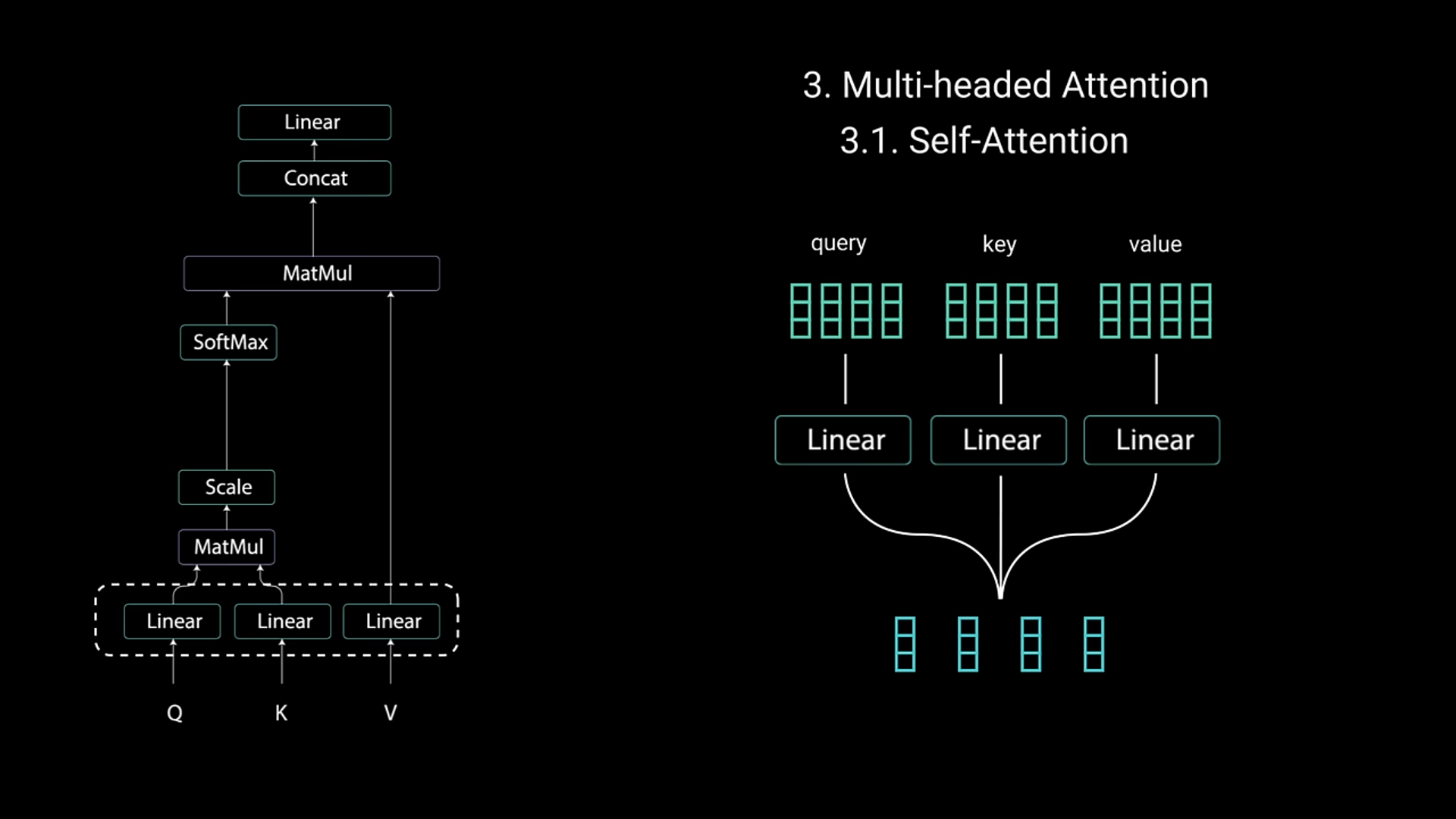
- Query and keys are used in a dot multiplication metrix that gives out scores of each value
- These values are then given importance
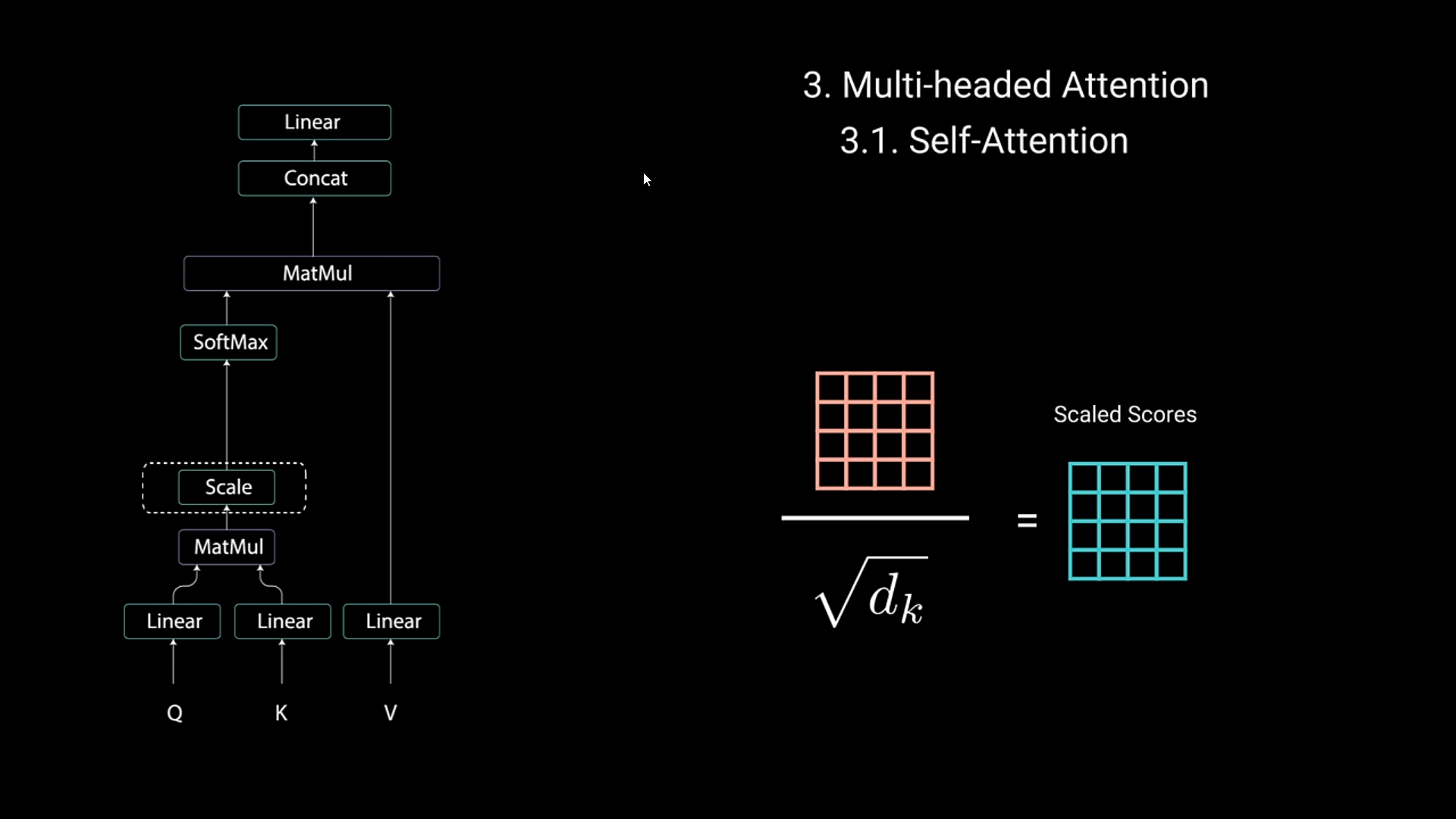
- In order to deal with more reliable info, you divide each word with their dimensions
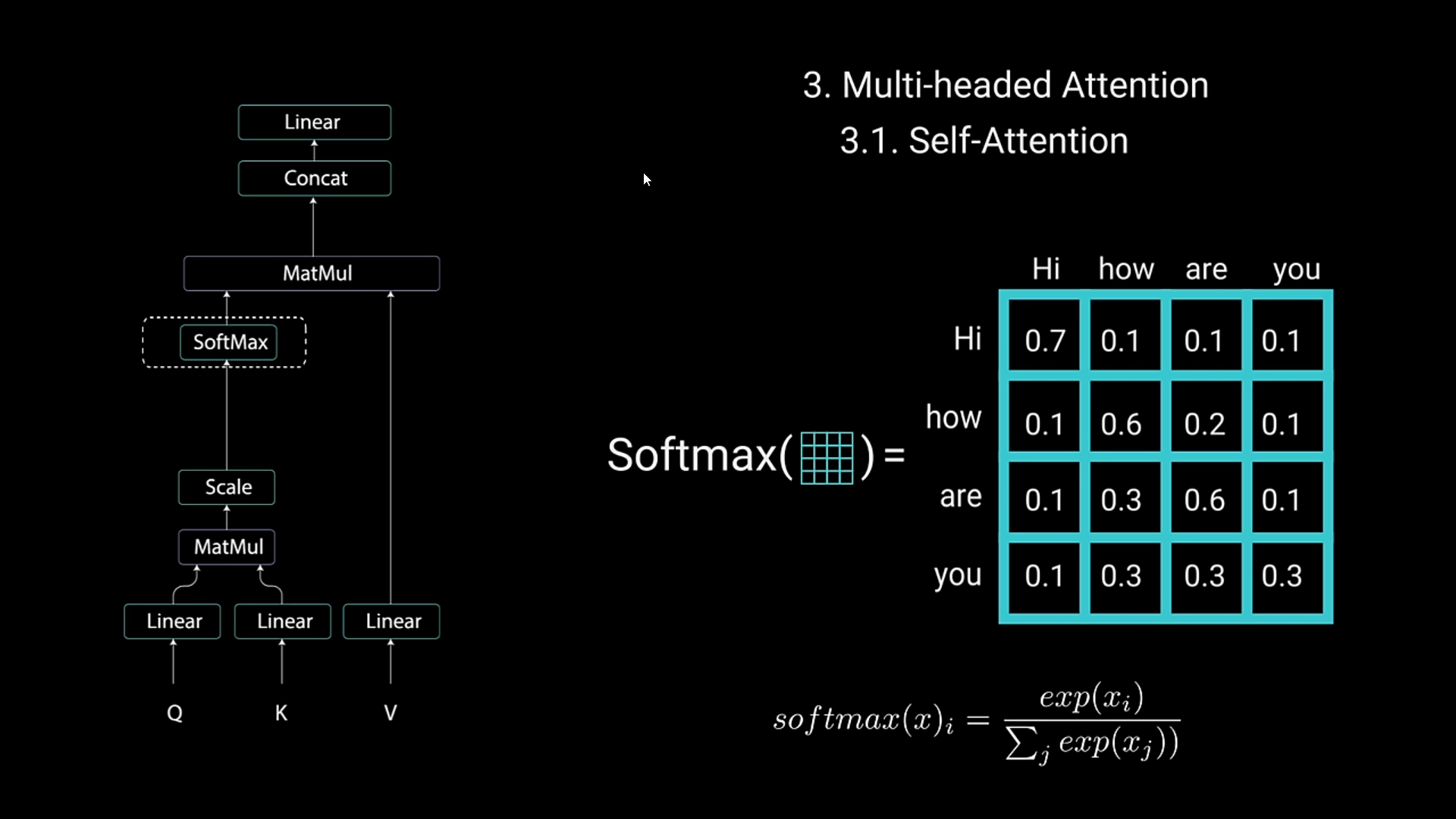
- It then gets applied Softmax Normalization in order to get values that are between 1 and 0
- Then each Self Attention Head would be used (in theory) to learn new things about that sentence or info
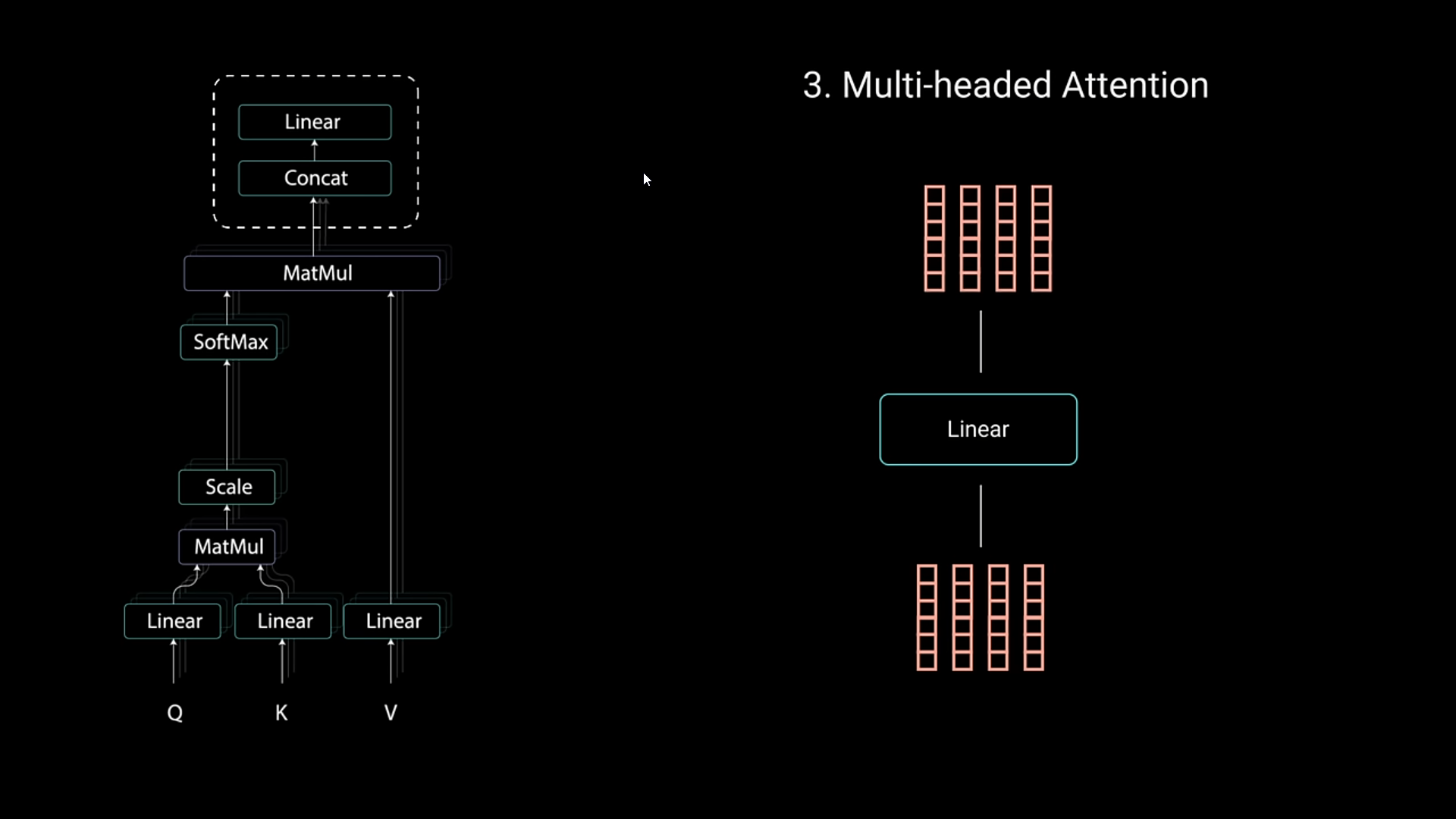
- At last, they’re passed onto a linear function to be later used
- O videonun kalanına bakmam lazim ama yetti yani o monoton ses